CompressGPT: Decrease Token Usage by ~70%
I saw @VictorTaelin's tweet recently on increasing the effective context window for GPT-* by asking the LLM to compress a prompt which is then fed into another instance of the same model. This seemed like a neat trick, but in practice presents some issues; the compression can be lossy, crucial instructions can be lost, and less characters != less tokens.
I set out to build a more usable version of this idea, and came up with CompressGPT. Through various techniques (described below) we can get a ~70% reduction in tokens for most LangChain tool-based prompts, with simply one line of code changed!
-from langchain import PromptTemplate
+from compress_gpt.langchain import CompressPrompt as PromptTemplateYou can install CompressGPT with a simple pip install compress-gpt, and the full docs can be found here.
Compression == Compilation?
There's something important to call out here—the process of compressing a prompt uses more than 1x tokens. Doesn't this defeat the purpose? Well, if you're only using this prompt once, then absolutely. However, if you're planning on calling a prompt several times (either within a single run or across multiple), then paying a one-time upfront cost to compress the prompt to something much cheaper & faster. That's exactly how CompressGPT is meant to be used: compilations are cached locally (to Redis or the file system) and intelligently re-used. You can specify whether prompts are cached before populating variables (CompressTemplate), or after (CompressPrompt), I found that this usage pattern matches most apps where minimizing token cost is important.
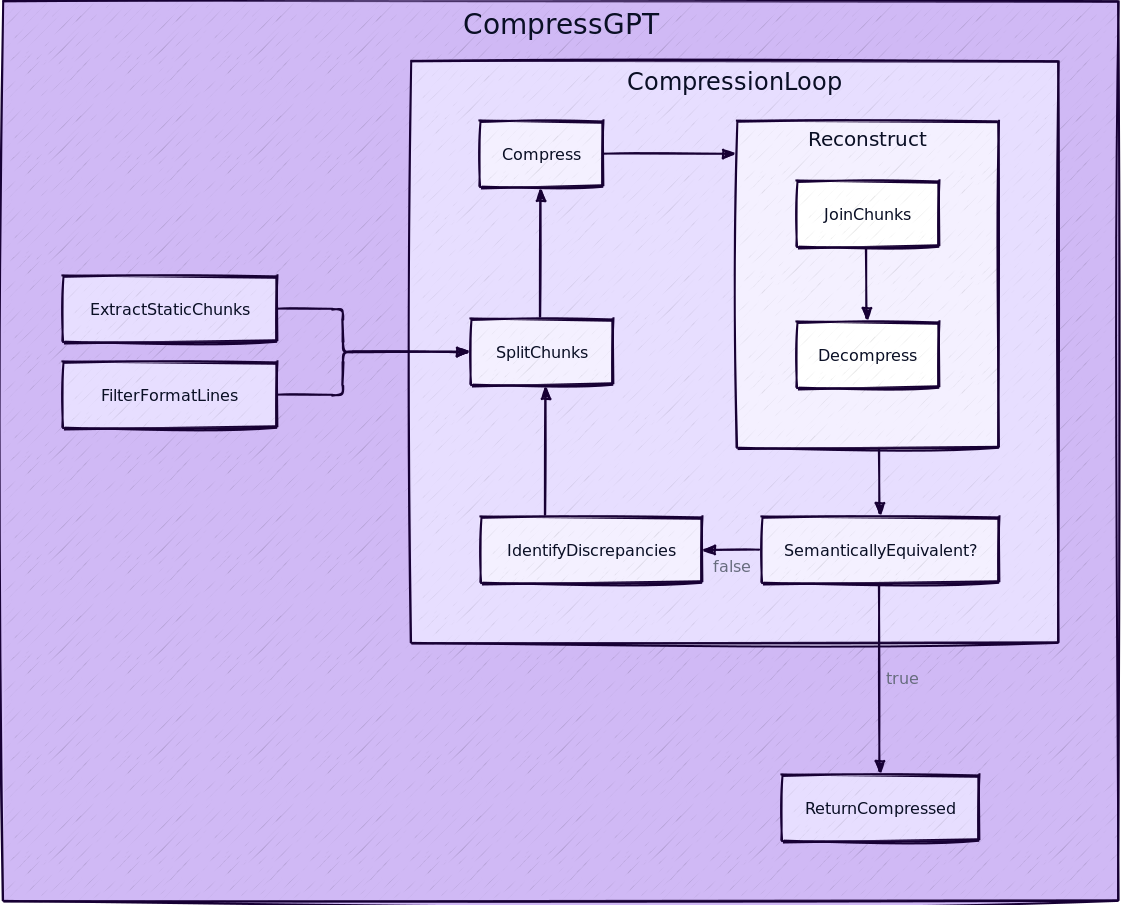
How CompressGPT Works
The high-level approach I took with CompressGPT is to figure out what can be safely compressed, and to what degree. This involves spinning off a bunch of sub-tasks (hence the increased token usage), compressing their outputs individually, then wrapping the whole thing back up again.
Let's use an example to explore the pipeline. I generated this prompt by creating a LangChain Agent with several Tools, including several Zapier NLA actions.
Original Prompt
System:
You are an assistant to a busy executive, Yasyf. Your goal is to make his life easier by helping automate communications.
You must be thorough in gathering all necessary context before taking an action.
Context:
- The current date and time are 2023-04-06 09:29:45
- The day of the week is Thursday
Information about Yasyf:
- His personal email is [email protected]. This is the calendar to use for personal events.
- His phone number is 415-631-6744. Use this as the "location" for any phone calls.
- He is an EIR at Root Ventures. Use this as the location for any meetings.
- He is in San Francisco, California. Use PST for scheduling.
Rules:
- Check if Yasyf is available before scheduling a meeting. If he is not, offer some alternate times.
- Do not create an event if it already exists.
- Do not create events in the past. Ensure that events you create are inserted at the correct time.
- Do not create an event if the time or date is ambiguous. Instead, ask for clarification.
You have access to the following tools:
Google Calendar: Find Event (Personal): A wrapper around Zapier NLA actions. The input to this tool is a natural language instruction, for example "get the latest email from my bank" or "send a slack message to the #general channel". Each tool will have params associated with it that are specified as a list. You MUST take into account the params when creating the instruction. For example, if the params are ['Message_Text', 'Channel'], your instruction should be something like 'send a slack message to the #general channel with the text hello world'. Another example: if the params are ['Calendar', 'Search_Term'], your instruction should be something like 'find the meeting in my personal calendar at 3pm'. Do not make up params, they will be explicitly specified in the tool description. If you do not have enough information to fill in the params, just say 'not enough information provided in the instruction, missing <param>'. If you get a none or null response, STOP EXECUTION, do not try to another tool!This tool specifically used for: Google Calendar: Find Event (Personal), and has params: ['Search_Term']
Google Calendar: Create Detailed Event: A wrapper around Zapier NLA actions. The input to this tool is a natural language instruction, for example "get the latest email from my bank" or "send a slack message to the #general channel". Each tool will have params associated with it that are specified as a list. You MUST take into account the params when creating the instruction. For example, if the params are ['Message_Text', 'Channel'], your instruction should be something like 'send a slack message to the #general channel with the text hello world'. Another example: if the params are ['Calendar', 'Search_Term'], your instruction should be something like 'find the meeting in my personal calendar at 3pm'. Do not make up params, they will be explicitly specified in the tool description. If you do not have enough information to fill in the params, just say 'not enough information provided in the instruction, missing <param>'. If you get a none or null response, STOP EXECUTION, do not try to another tool!This tool specifically used for: Google Calendar: Create Detailed Event, and has params: ['Summary', 'Start_Date___Time', 'Description', 'Location', 'End_Date___Time', 'Attendees']
Google Contacts: Find Contact: A wrapper around Zapier NLA actions. The input to this tool is a natural language instruction, for example "get the latest email from my bank" or "send a slack message to the #general channel". Each tool will have params associated with it that are specified as a list. You MUST take into account the params when creating the instruction. For example, if the params are ['Message_Text', 'Channel'], your instruction should be something like 'send a slack message to the #general channel with the text hello world'. Another example: if the params are ['Calendar', 'Search_Term'], your instruction should be something like 'find the meeting in my personal calendar at 3pm'. Do not make up params, they will be explicitly specified in the tool description. If you do not have enough information to fill in the params, just say 'not enough information provided in the instruction, missing <param>'. If you get a none or null response, STOP EXECUTION, do not try to another tool!This tool specifically used for: Google Contacts: Find Contact, and has params: ['Search_By']
Google Calendar: Delete Event: A wrapper around Zapier NLA actions. The input to this tool is a natural language instruction, for example "get the latest email from my bank" or "send a slack message to the #general channel". Each tool will have params associated with it that are specified as a list. You MUST take into account the params when creating the instruction. For example, if the params are ['Message_Text', 'Channel'], your instruction should be something like 'send a slack message to the #general channel with the text hello world'. Another example: if the params are ['Calendar', 'Search_Term'], your instruction should be something like 'find the meeting in my personal calendar at 3pm'. Do not make up params, they will be explicitly specified in the tool description. If you do not have enough information to fill in the params, just say 'not enough information provided in the instruction, missing <param>'. If you get a none or null response, STOP EXECUTION, do not try to another tool!This tool specifically used for: Google Calendar: Delete Event, and has params: ['Event', 'Notify_Attendees_', 'Calendar']
Google Calendar: Update Event: A wrapper around Zapier NLA actions. The input to this tool is a natural language instruction, for example "get the latest email from my bank" or "send a slack message to the #general channel". Each tool will have params associated with it that are specified as a list. You MUST take into account the params when creating the instruction. For example, if the params are ['Message_Text', 'Channel'], your instruction should be something like 'send a slack message to the #general channel with the text hello world'. Another example: if the params are ['Calendar', 'Search_Term'], your instruction should be something like 'find the meeting in my personal calendar at 3pm'. Do not make up params, they will be explicitly specified in the tool description. If you do not have enough information to fill in the params, just say 'not enough information provided in the instruction, missing <param>'. If you get a none or null response, STOP EXECUTION, do not try to another tool!This tool specifically used for: Google Calendar: Update Event, and has params: ['Show_me_as_Free_or_Busy', 'Location', 'Calendar', 'Event', 'Summary', 'Attendees', 'Description']
Google Calendar: Add Attendee/s to Event: A wrapper around Zapier NLA actions. The input to this tool is a natural language instruction, for example "get the latest email from my bank" or "send a slack message to the #general channel". Each tool will have params associated with it that are specified as a list. You MUST take into account the params when creating the instruction. For example, if the params are ['Message_Text', 'Channel'], your instruction should be something like 'send a slack message to the #general channel with the text hello world'. Another example: if the params are ['Calendar', 'Search_Term'], your instruction should be something like 'find the meeting in my personal calendar at 3pm'. Do not make up params, they will be explicitly specified in the tool description. If you do not have enough information to fill in the params, just say 'not enough information provided in the instruction, missing <param>'. If you get a none or null response, STOP EXECUTION, do not try to another tool!This tool specifically used for: Google Calendar: Add Attendee/s to Event, and has params: ['Event', 'Attendee_s', 'Calendar']
Gmail: Find Email (Personal): A wrapper around Zapier NLA actions. The input to this tool is a natural language instruction, for example "get the latest email from my bank" or "send a slack message to the #general channel". Each tool will have params associated with it that are specified as a list. You MUST take into account the params when creating the instruction. For example, if the params are ['Message_Text', 'Channel'], your instruction should be something like 'send a slack message to the #general channel with the text hello world'. Another example: if the params are ['Calendar', 'Search_Term'], your instruction should be something like 'find the meeting in my personal calendar at 3pm'. Do not make up params, they will be explicitly specified in the tool description. If you do not have enough information to fill in the params, just say 'not enough information provided in the instruction, missing <param>'. If you get a none or null response, STOP EXECUTION, do not try to another tool!This tool specifically used for: Gmail: Find Email (Personal), and has params: ['Search_String']
The way you use the tools is by specifying a json blob.
Specifically, this json should have a `action` key (with the name of the tool to use) and a `action_input` key (with the input to the tool going here).
The only values that should be in the "action" field are: Google Calendar: Find Event (Personal), Google Calendar: Create Detailed Event, Google Contacts: Find Contact, Google Calendar: Delete Event, Google Calendar: Update Event, Google Calendar: Add Attendee/s to Event, Gmail: Find Email (Personal).
The $JSON_BLOB should only contain a SINGLE action, do NOT return a list of multiple actions. Here is an example of a valid $JSON_BLOB:
```
{
"action": $TOOL_NAME,
"action_input": $INPUT
}
```
ALWAYS use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action:
```
$JSON_BLOB
```
Observation: the result of the action
... (this Thought/Action/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin! Reminder to always use the exact characters `Final Answer` when responding.
Step 1: Preprocessing
The preprocessing step largely consists of identifying and extracting information that should not be (fully) compressed, across two subroutines.
The first subroutine filters the lines of the prompt to only retain those which apply constraints on the format of the output. These are lines describing schemas, text formats, and value constraints. We extract these because they should have much more conservative compression applied to them to retain valid output.
Format Sentences
The way you use the tools is by specifying a json blob.
Specifically, this json should have a `action` key (with the name of the tool to use) and a `action_input` key (with the input to the tool going here).
The only values that should be in the "action" field are: Google Calendar: Find Event (Personal), Google Calendar: Create Detailed Event, Google Contacts: Find Contact, Google Calendar: Delete Event, Google Calendar: Update Event, Google Calendar: Add Attendee/s to Event, Gmail: Find Email (Personal)
The $JSON_BLOB should only contain a SINGLE action, do NOT return a list of multiple actions. Here is an example of a valid $JSON_BLOB:
```
{
"action": $TOOL_NAME,
"action_input": $INPUT
}
```
ALWAYS use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action:
```
$JSON_BLOB
```
Observation: the result of the action
... (this Thought/Action/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
The second subroutine extracts a lookup table of "static chunks": strings which must be represented verbatim in the final prompt. Think parameter names/values, picklists, and proper nouns. This lookup table is propagated throughout, and the model is instructed to output references whenever it wants to compress a static chunk. The final step of the pipeline then subs those values back in for the references.
Static Chunks
- 0: 2023-04-06 09:29:45
- 1: `Final Answer`
- 2: ['Event', 'Attendee_s', 'Calendar']
- 3: Google Calendar: Delete Event
- 4: Google Calendar: Create Detailed Event
- 5: ['Event', 'Notify_Attendees_', 'Calendar']
- 6: ['Search_By']
- 7: San Francisco, California
- 8: EIR
- 9: [email protected]
- 10: Google Contacts: Find Contact
- 11: ['Summary', 'Start_Date___Time', 'Description', 'Location', 'End_Date___Time', 'Attendees']
- 12: ['Show_me_as_Free_or_Busy', 'Location', 'Calendar', 'Event', 'Summary', 'Attendees', 'Description']
- 13: Google Calendar: Update Event
- 14: Google Calendar: Find Event (Personal)
- 15: Thursday
- 16: Google Calendar: Add Attendee/s to Event
- 17: PST
- 18: Gmail: Find Email (Personal)
- 19: Root Ventures
- 20: ['Search_Term']
- 21: 415-631-6744
- 22: ['Search_String']
Step 2: Split & Compress
This subroutine uses GPT-4 to split the prompt into a series of chunks, each representing either a string to be compressed, or a reference to a static chunk. The string chunks are then compressed to minimize token count, while attempting to be lossless. It's ok if we are loss here, as we have a semantic equivalence check that follows.
Chunks
# Plan:
# 1. In the "Rules" section, add specific information on offering alternate times and asking for clarification if time/date is ambiguous.
# 2. For each tool description, include detailed explanations and usage with given params.
# 3. Provide an explanation and example of a valid JSON_BLOB.
# 4. Specify stopping execution conditions: when a none or null response is received, in each tool descriptions.
[
{"m": "c", "t": "U r assistant 2 busy exec,Yasyf."},
{"m": "c", "t": "Automate comms&gather context."},
{"m": "c", "t": "Currnt date&time:"},
{"m": "r", "i": 0},
{"m": "c", "t": "day wt is:"},
{"m": "r", "i": 15},
{"m": "c", "t": "Yasyf info: email-"},
{"m": "r", "i": 9},
{"m": "c", "t": "phn#:"},
{"m": "r", "i": 21},
{"m": "c", "t": "EIR@"},
{"m": "r", "i": 19},
{"m": "c", "t": ",loc:"},
{"m": "r", "i": 7},
{"m": "c", "t": ",use PST 4 sched. Rules: Check availabilty, offer altn8 times, don't create duplicates, past events, ambiguous times; ask clarification."},
{"m": "c", "t": "Access tools nm & params: 1."},
{"m": "r", "i": 14},
{"m": "c", "t": "{"},
{"m": "r", "i": 20},
{"m": "c", "t": "} 2."},
{"m": "r", "i": 4},
{"m": "c", "t": "{"},
{"m": "r", "i": 11},
{"m": "c", "t": "} 3."},
{"m": "r", "i": 10},
{"m": "c", "t": "{"},
{"m": "r", "i": 6},
{"m": "c", "t": "} 4."},
{"m": "r", "i": 3},
{"m": "c", "t": "{"},
{"m": "r", "i": 5},
{"m": "c", "t": "} 5."},
{"m": "r", "i": 13},
{"m": "c", "t": "{"},
{"m": "r", "i": 12},
{"m": "c", "t": "} 6."},
{"m": "r", "i": 16},
{"m": "c", "t": "{"},
{"m": "r", "i": 2},
{"m": "c", "t": "} 7."},
{"m": "r", "i": 18},
{"m": "c", "t": "{"},
{"m": "r", "i": 22},
{"m": "c", "t": "}"},
{"m": "c", "t": "Use tools by specifyng JSON_BLOB: {\"action\": $TOOL_NAME,\"action_input\": $INPUT}.answerQ->think->Action->Observe->(repeat)->Final Ans."},
{"m": "c", "t": "Begin!use `FinalAnswer` when Response."}
]
Step 3: Reconstruct & Check
The goal of this step is to ensure that our compressed prompt is semantically equivalent with the original. We do this by forcing GPT-4 to decompress the prompt, revealing the latent representation it would have while acting. This happens without any additional context.
The reconstructed prompt is then diffed against the original, and any meaningful differences are noted. If there are none, we're ready to return the compressed prompt. Otherwise, we build a list of discrepancies to feed in as additional input to Step 2.
Reconstructed Prompt
You are an assistant to a busy executive, Yasyf. Your job is to automate communications and gather context. The current date and time is 2023-04-06 09:29:45. The day of the week is Thursday. Yasyf's information includes his email, which is [email protected], his phone number, which is 415-631-6744, and his position as an EIR at Root Ventures. Yasyf is located in San Francisco, California, and you should use PST for scheduling purposes.
The rules for managing Yasyf's schedule are as follows:
- Check availability
- Offer alternative times
- Do not create duplicate events
- Do not schedule events in the past
- Handle ambiguous times with care and ask for clarification when needed
You have access to the following tools along with their parameters:
Google Calendar: Find Event (Personal)
{
['Search_Term']
}
Google Calendar: Create Detailed Event
{
['Summary', 'Start_Date___Time', 'Description', 'Location', 'End_Date___Time', 'Attendees']
}
Google Contacts: Find Contact
{
['Search_By']
}
Google Calendar: Delete Event
{
['Event', 'Notify_Attendees_', 'Calendar']
}
Google Calendar: Update Event
{
['Show_me_as_Free_or_Busy', 'Location', 'Calendar', 'Event', 'Summary', 'Attendees', 'Description']
}
Google Calendar: Add Attendee/s to Event
{
['Event', 'Attendee_s', 'Calendar']
}
Gmail: Find Email (Personal)
{
['Search_String']
}
To use these tools, specify a JSON_BLOB as follows: {"action": $TOOL_NAME,"action_input": $INPUT}. When answering questions related to this process, think, take action, observe, and repeat as necessary. When submitting your response, use the phrase `Final Answer`.
Step 4: Return Compressed Prompt
Once we're sure our compressed and original prompts would render equally valid results, we wrap the compressed prompt in a brief meta-prompt that instructs GPT-4 to decompress the prompt "in memory" before acting on it. We also include the verbatim formatting instructions to make sure the output is similarly parseable.
# Original Response
{
"action": "Google Calendar: Find Event (Personal)",
"action_input": {"Search_Term": "2023-04-06 19:30:00"},
}
# Compressed Response (2200 tks -> 647 tks, 70.59% savings)
{
"action": "Google Calendar: Find Event (Personal)",
"action_input": {"Search_Term": "Find any event for April 6 at 7:30 PM"}
}Borrowing from ML Training Methods
A few techniques here were inspired by classic ML training hacks.
The first is emulating the autoencoder model. We "train" the model by forcing GPT to learn an reduced-dimensionality representation of the prompt (the compressed version == the hidden state), and then attempt reconstruct it's input. We then give it an "error function" (diff) to calculate a "loss" (discrepancies), which are used to perturb the way the model acts on future iterations. The hidden state that's learned is then our desired value: the compressed prompt. Pretty meta, eh!
The other weird idea that was inspired by training was the idea of mixed-precision training. While training a model, there are different levels of precision with which to represent the data & weights (just numbers!). In an ideal world, we'd always want to use the most precise representation. However, this is very time-and-space expensive. So the idea behind mixed precision training is to convert the numbers in realtime to a lower precision format whenever the operation at hand can tolerate it. When we can use the cheap, quick format without suffering much, we do. When it's important to be as precise as possible, we use the expensive one.
How did I do this with CompressGPT? By altering the GPT model being used for a given task. Simple tasks like fixing invalid JSON or diffing two paragraphs use gpt-3.5-turbo, while complex tasks like the compression itself use gpt-4. I've clearly been reading too many PyTorch PRs if the first thing my brain went to here is AMP, but it's pretty apt!
So, Should I Use It?
Maybe! For long prompts, especially those that are repetitive, this approach works quite well. Notably, it is very performant on the kinds of prompts langchain generates when using multiple Tools. On shorter/simpler prompts, the increased token count from using less common words normally outweighs the benefits of the compression. Note this also depends on the tokenizer your model is using!
Sometimes, using CompressSimpleTemplate and CompressSimplePrompt can perform better for short prompts. These skip a bunch of steps not needed for very simple instructions. YMMV!
n.b. I wasn't able to see any compression consistently work with a model older than gpt-4. gpt-3.5-turbo sometimes does a good job, but I wouldn't risk it.
Member discussion